Postgres
Airbyte's certified Postgres connector offers the following features:
- Replicate data from tables, views and materilized views. Other data objects won't be replicated to the destination like indexes, permissions.
- Multiple methods of keeping your data fresh, including Change Data Capture (CDC) and replication using the xmin system column.
- All available sync modes, providing flexibility in how data is delivered to your destination.
- Reliable replication at any table size with checkpointing and chunking of database reads.
The contents below include a 'Quick Start' guide, advanced setup steps, and reference information (data type mapping, and changelogs). See here to troubleshooting issues with the Postgres connector.
Quick Start
Here is an outline of the minimum required steps to configure a Postgres connector:
- Create a dedicated read-only Postgres user with permissions for replicating data
- Create a new Postgres source in the Airbyte UI using
xminsystem column - (Airbyte Cloud Only) Allow inbound traffic from Airbyte IPs
Once this is complete, you will be able to select Postgres as a source for replicating data.
Step 1: Create a dedicated read-only Postgres user
These steps create a dedicated read-only user for replicating data. Alternatively, you can use an existing Postgres user in your database.
The following commands will create a new user:
CREATE USER <user_name> PASSWORD 'your_password_here';
Now, provide this user with read-only access to relevant schemas and tables. Re-run this command for each schema you expect to replicate data from:
GRANT USAGE ON SCHEMA <schema_name> TO <user_name>;
GRANT SELECT ON ALL TABLES IN SCHEMA <schema_name> TO <user_name>;
ALTER DEFAULT PRIVILEGES IN SCHEMA <schema_name> GRANT SELECT ON TABLES TO <user_name>;
Step 2: Create a new Postgres source in Airbyte UI
From your Airbyte Cloud or Airbyte Open Source account, select Sources from the left navigation bar, search for Postgres, then create a new Postgres source.
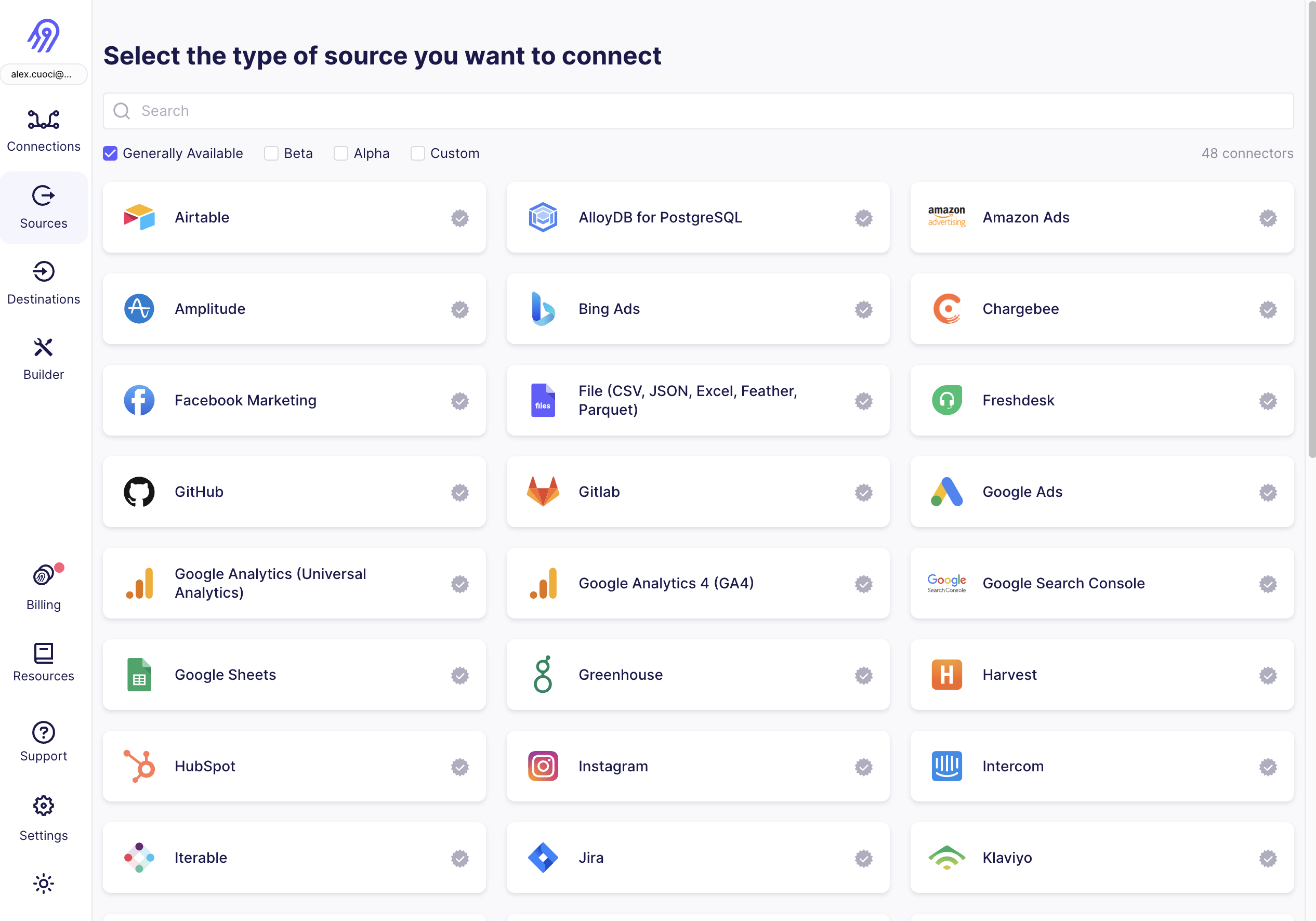
To fill out the required information:
- Enter the hostname, port number, and name for your Postgres database.
- You may optionally opt to list each of the schemas you want to sync. These are case-sensitive, and multiple schemas may be entered. By default,
publicis the only selected schema. - Enter the username and password you created in Step 1.
- Select an SSL mode. You will most frequently choose
requireorverify-ca. Both of these always require encryption.verify-caalso requires certificates from your Postgres database. See here to learn about other SSL modes and SSH tunneling. - Select
Standard (xmin)from available replication methods. This uses the xmin system column to reliably replicate data from your database.- If your database is particularly large (> 500 GB), you will benefit from configuring your Postgres source using logical replication (CDC).
Step 3: (Airbyte Cloud Only) Allow inbound traffic from Airbyte IPs.
If you are on Airbyte Cloud, you will always need to modify your database configuration to allow inbound traffic from Airbyte IPs. You can find a list of all IPs that need to be allowlisted in our Airbyte Security docs.
Now, click Set up source in the Airbyte UI. Airbyte will now test connecting to your database. Once this succeeds, you've configured an Airbyte Postgres source!
Advanced Configuration
Setup using CDC
Airbyte uses logical replication of the Postgres write-ahead log (WAL) to incrementally capture deletes using a replication plugin:
- See here to learn more on how Airbyte implements CDC.
- See here to learn more about Postgres CDC requirements and limitations.
We recommend configuring your Postgres source with CDC when:
- You need a record of deletions.
- You have a very large database (500 GB or more).
- Your table has a primary key but doesn't have a reasonable cursor field for incremental syncing (
updated_at).
These are the additional steps required (after following the quick start) to configure your Postgres source using CDC:
- Provide additional
REPLICATIONpermissions to read-only user - Enable logical replication on your Postgres database
- Create a replication slot on your Postgres database
- Create publication and replication identities for each Postgres table
- Enable CDC replication in the Airbyte UI
Step 1: Prepopulate your Postgres source configuration
We recommend following the steps in the quick start section to confirm that Airbyte can connect to your Postgres database prior to configuring CDC settings.
For CDC, you must connect to primary/master databases. Pointing the connector configuration to replica database hosts for CDC will lead to failures.
Step 2: Provide additional permissions to read-only user
To configure CDC for the Postgres source connector, grant REPLICATION permissions to the user created in step 1 of the quick start:
ALTER USER <user_name> REPLICATION;
Step 3: Enable logical replication on your Postgres database
To enable logical replication on bare metal, VMs (EC2/GCE/etc), or Docker, configure the following parameters in the postgresql.conf file for your Postgres database:
| Parameter | Description | Set value to |
|---|---|---|
| wal_level | Type of coding used within the Postgres write-ahead log | logical |
| max_wal_senders | The maximum number of processes used for handling WAL changes | min: 1 |
| max_replication_slots | The maximum number of replication slots that are allowed to stream WAL changes | 1 (if Airbyte is the only service reading subscribing to WAL changes. More than 1 if other services are also reading from the WAL) |
To enable logical replication on AWS Postgres RDS or Aurora:
- Go to the Configuration tab for your DB cluster.
- Find your cluster parameter group. Either edit the parameters for this group or create a copy of this parameter group to edit. If you create a copy, change your cluster's parameter group before restarting.
- Within the parameter group page, search for
rds.logical_replication. Select this row and click Edit parameters. Set this value to 1. - Wait for a maintenance window to automatically restart the instance or restart it manually.
To enable logical replication on Azure Database for Postgres, change the replication mode of your Postgres DB on Azure to logical using the replication menu of your PostgreSQL instance in the Azure Portal. Alternatively, use the Azure CLI to run the following command:
az postgres server configuration set --resource-group group --server-name server --name azure.replication_support --value logical
az postgres server restart --resource-group group --name server
Step 4: Create a replication slot on your Postgres database
Airbyte requires a replication slot configured only for its use. Only one source should be configured that uses this replication slot.
For this step, Airbyte requires use of the pgoutput plugin. To create a replication slot called airbyte_slot using pgoutput, run as the user with the newly granted REPLICATION role:
SELECT pg_create_logical_replication_slot('airbyte_slot', 'pgoutput');
The output of this command will include the name of the replication slot to fill into the Airbyte source setup page.
Step 5: Create publication and replication identities for each Postgres table
For each table you want to replicate with CDC, follow the steps below:
- Add the replication identity (the method of distinguishing between rows) for each table you want to replicate:
ALTER TABLE tbl1 REPLICA IDENTITY DEFAULT;
In rare cases, if your tables use data types that support TOAST or have very large field values, consider instead using replica identity type full: ALTER TABLE tbl1 REPLICA IDENTITY FULL;.
- Create the Postgres publication. You should include all tables you want to replicate as part of the publication:
CREATE PUBLICATION airbyte_publication FOR TABLE <tbl1, tbl2, tbl3>;`
The publication name is customizable. Refer to the Postgres docs if you need to add or remove tables from your publication in the future.
The Airbyte UI currently allows selecting any tables for CDC. If a table is selected that is not part of the publication, it will not be replicated even though it is selected. If a table is part of the publication but does not have a replication identity, that replication identity will be created automatically on the first run if the Airbyte user has the necessary permissions.
Step 6: Enable CDC replication in Airbyte UI
In your Postgres source, change the replication mode to Logical Replication (CDC), and enter the replication slot and publication you just created.
Postgres Replication Methods
The Postgres source currently offers 3 methods of replicating updates to your destination: CDC, xmin and standard (with a user defined cursor). Both CDC and xmin are the most reliable methods of updating your data.
CDC
Airbyte uses logical replication of the Postgres write-ahead log (WAL) to incrementally capture deletes using a replication plugin. To learn more how Airbyte implements CDC, refer to Change Data Capture (CDC). We recommend configuring your Postgres source with CDC when:
- You need a record of deletions.
- You have a very large database (500 GB or more).
- Your table has a primary key but doesn't have a reasonable cursor field for incremental syncing (
updated_at).
If your goal is to maintain a snapshot of your table in the destination but the limitations prevent you from using CDC, consider using the xmin replication method.
Xmin
Xmin replication is the new cursor-less replication method for Postgres. Cursorless syncs enable syncing new or updated rows without explicitly choosing a cursor field. The xmin system column which (available in all Postgres databases) is used to track inserts and updates to your source data.
This is a good solution if:
- There is not a well-defined cursor candidate to use for Standard incremental mode.
- You want to replace a previously configured full-refresh sync.
- You are replicating Postgres tables less than 500GB.
- You are not replicating non-materialized views. Non-materialized views are not supported by xmin replication.
Connecting with SSL or SSH Tunneling
SSL Modes
Airbyte Cloud uses SSL by default. You are not permitted to disable SSL while using Airbyte Cloud.
Here is a breakdown of available SSL connection modes:
disableto disable encrypted communication between Airbyte and the sourceallowto enable encrypted communication only when required by the sourcepreferto allow unencrypted communication only when the source doesn't support encryptionrequireto always require encryption. Note: The connection will fail if the source doesn't support encryption.verify-cato always require encryption and verify that the source has a valid SSL certificateverify-fullto always require encryption and verify the identity of the source
SSH Tunneling
If you are using SSH tunneling, as Airbyte Cloud requires encrypted communication, select SSH Key Authentication or Password Authentication if you selected disable, allow, or prefer as the SSL Mode; otherwise, the connection will fail.
For SSH Tunnel Method, select:
No Tunnelfor a direct connection to the databaseSSH Key Authenticationto use an RSA Private as your secret for establishing the SSH tunnelPassword Authenticationto use a password as your secret for establishing the SSH tunnel
Connect via SSH Tunnel
You can connect to a Postgres instance via an SSH tunnel.
When using an SSH tunnel, you are configuring Airbyte to connect to an intermediate server (also called a bastion or a jump server) that has direct access to the database. Airbyte connects to the bastion and then asks the bastion to connect directly to the server.
To connect to a Postgres instance via an SSH tunnel:
- While setting up the Postgres source connector, from the SSH tunnel dropdown, select:
- SSH Key Authentication to use a private as your secret for establishing the SSH tunnel
- Password Authentication to use a password as your secret for establishing the SSH Tunnel
- For SSH Tunnel Jump Server Host, enter the hostname or IP address for the intermediate (bastion) server that Airbyte will connect to.
- For SSH Connection Port, enter the port on the bastion server. The default port for SSH connections is 22.
- For SSH Login Username, enter the username to use when connecting to the bastion server. Note: This is the operating system username and not the Postgres username.
- For authentication:
- If you selected SSH Key Authentication, set the SSH Private Key to the private Key that you are using to create the SSH connection.
- If you selected Password Authentication, enter the password for the operating system user to connect to the bastion server. Note: This is the operating system password and not the Postgres password.
Generating a private key for SSH Tunneling
The connector supports any SSH compatible key format such as RSA or Ed25519. To generate an RSA key, for example, run:
ssh-keygen -t rsa -m PEM -f myuser_rsa
The command produces the private key in PEM format and the public key remains in the standard format used by the authorized_keys file on your bastion server. Add the public key to your bastion host to the user you want to use with Airbyte. The private key is provided via copy-and-paste to the Airbyte connector configuration screen to allow it to log into the bastion server.
Limitations & Troubleshooting
To see connector limitations, or troubleshoot your Postgres connector, see more in our Postgres troubleshooting guide.
Data type mapping
According to Postgres documentation, Postgres data types are mapped to the following data types when synchronizing data. You can check the test values examples here. If you can't find the data type you are looking for or have any problems feel free to add a new test!
| Postgres Type | Resulting Type | Notes |
|---|---|---|
bigint | number | |
bigserial, serial8 | number | |
bit | string | Fixed-length bit string (e.g. "0100"). |
bit varying, varbit | string | Variable-length bit string (e.g. "0100"). |
boolean, bool | boolean | |
box | string | |
bytea | string | Variable length binary string with hex output format prefixed with "\x" (e.g. "\x6b707a"). |
character, char | string | |
character varying, varchar | string | |
cidr | string | |
circle | string | |
date | string | Parsed as ISO8601 date time at midnight. CDC mode doesn't support era indicators. Issue: #14590 |
double precision, float, float8 | number | Infinity, -Infinity, and NaN are not supported and converted to null. Issue: #8902. |
hstore | string | |
inet | string | |
integer, int, int4 | number | |
interval | string | |
json | string | |
jsonb | string | |
line | string | |
lseg | string | |
macaddr | string | |
macaddr8 | string | |
money | number | |
numeric, decimal | number | Infinity, -Infinity, and NaN are not supported and converted to null. Issue: #8902. |
path | string | |
pg_lsn | string | |
point | string | |
polygon | string | |
real, float4 | number | |
smallint, int2 | number | |
smallserial, serial2 | number | |
serial, serial4 | number | |
text | string | |
time | string | Parsed as a time string without a time-zone in the ISO-8601 calendar system. |
timetz | string | Parsed as a time string with time-zone in the ISO-8601 calendar system. |
timestamp | string | Parsed as a date-time string without a time-zone in the ISO-8601 calendar system. |
timestamptz | string | Parsed as a date-time string with time-zone in the ISO-8601 calendar system. |
tsquery | string | |
tsvector | string | |
uuid | string | |
xml | string | |
enum | string | |
tsrange | string | |
array | array | E.g. "["10001","10002","10003","10004"]". |
| composite type | string |
Changelog
| Version | Date | Pull Request | Subject |
|---|---|---|---|
| 3.3.27 | 2024-04-22 | 37441 | Remove legacy bad values handling code. |
| 3.3.26 | 2024-04-10 | 36982 | Populate airyte_meta.changes for xmin path |
| 3.3.25 | 2024-04-10 | 36981 | Track latest CDK |
| 3.3.24 | 2024-04-10 | 36865 | Track latest CDK |
| 3.3.23 | 2024-04-02 | 36759 | Track latest CDK |
| 3.3.22 | 2024-04-01 | 36739 | Fix useLocalCdk flag. |
| 3.3.21 | 2024-03-25 | 36584 | Adopt Kotlin CDK. |
| 3.3.20 | 2024-03-25 | 36432 | Failure to serialize values from Postgres DB shouldn't fail sync. |
| 3.3.19 | 2024-03-12 | 36333 | Use newest CDK - deprecate dbz iterator |
| 3.3.18 | 2024-03-12 | 35599 | Use newest CDK |
| 3.3.17 | 2024-03-12 | 35939 | Use lsn_commit value instead of lsn_proc for CDC checkpointing logic. |
| 3.3.16 | 2024-03-11 | 35904 | Adopt Java CDK 0.23.1- debezium retries. |
| 3.3.15 | 2024-02-29 | 34724 | Add record count in state message. |
| 3.3.14 | 2024-03-06 | 35842 | Add logging to understand cases with a large number of records with the same LSN. |
| 3.3.13 | 2024-02-27 | 35675 | Fix invalid cdc error message. |
| 3.3.12 | 2024-02-22 | 35569 | Fix logging bug. |
| 3.3.11 | 2024-02-20 | 35304 | Add config to throw an error on invalid CDC position and enable it by default. |
| 3.3.10 | 2024-02-13 | 35036 | Emit analytics message for invalid CDC cursor. |
| 3.3.9 | 2024-02-13 | 35224 | Adopt CDK 0.20.4 |
| 3.3.8 | 2024-02-08 | 34751 | Adopt CDK 0.19.0 |
| 3.3.7 | 2024-02-08 | 34781 | Add a setting in the setup page to advance the LSN. |
| 3.3.6 | 2024-02-07 | 34892 | Adopt CDK v0.16.6 |
| 3.3.5 | 2024-02-07 | 34948 | Adopt CDK v0.16.5 |
| 3.3.4 | 2024-01-31 | 34723 | Adopt CDK v0.16.3 |
| 3.3.3 | 2024-01-26 | 34573 | Adopt CDK v0.16.0 |
| 3.3.2 | 2024-01-24 | 34465 | Check xmin only if user selects xmin sync mode. |
| 3.3.1 | 2024-01-10 | 34119 | Adopt java CDK version 0.11.5. |
| 3.3.0 | 2023-12-19 | 33437 | Remove LEGACY state flag |
| 3.2.27 | 2023-12-18 | 33605 | Advance Postgres LSN for PG 14 & below. |
| 3.2.26 | 2023-12-11 | 33027 | Support for better debugging tools. |
| 3.2.25 | 2023-11-29 | 32961 | Bump debezium wait time default to 20 min. |
| 3.2.24 | 2023-11-28 | 32686 | Better logging to understand dbz closing reason attribution. |
| 3.2.23 | 2023-11-28 | 32891 | Fix CDK dependency in build. |
| 3.2.22 | 2023-11-22 | 32656 | Adopt java CDK version 0.5.0. |
| 3.2.21 | 2023-11-07 | 31856 | handle date/timestamp infinity values properly |
| 3.2.20 | 2023-11-06 | 32193 | Adopt java CDK version 0.4.1. |
| 3.2.19 | 2023-11-03 | 32050 | Adopt java CDK version 0.4.0. |
| 3.2.18 | 2023-11-01 | 29038 | Fix typo (s/Airbtye/Airbyte/) |
| 3.2.17 | 2023-11-01 | 32068 | Bump Debezium 2.2.0Final -> 2.4.0Final |
| 3.2.16 | 2023-10-31 | 31976 | Speed up tests involving Debezium |
| 3.2.15 | 2023-10-30 | 31960 | Adopt java CDK version 0.2.0. |
| 3.2.14 | 2023-10-24 | 31792 | Fix error message link on issue with standby |
| 3.2.14 | 2023-10-24 | 31792 | fail sync when debezeum fails to shutdown cleanly |
| 3.2.13 | 2023-10-16 | 31029 | Enforces encrypted traffic settings when env var DEPLOYMENT_MODE = CLOUD. |
| 3.1.13 | 2023-10-13 | 31309 | Addressed decimals being incorrectly deserialized into scientific notation. |
| 3.1.12 | 2023-10-12 | 31328 | Improvements to initial load of tables in older versions of postgres. |
| 3.1.11 | 2023-10-11 | 31322 | Correct pevious release |
| 3.1.10 | 2023-09-29 | 30806 | Cap log line length to 32KB to prevent loss of records. |
| 3.1.9 | 2023-09-25 | 30534 | Fix JSONB[] column type handling bug. |
| 3.1.8 | 2023-09-20 | 30125 | Improve initial load performance for older versions of PostgreSQL. |
| 3.1.7 | 2023-09-05 | 29672 | Handle VACUUM happening during initial sync |
| 3.1.6 | 2023-08-24 | 29821 | Set replication_method display_type to radio, update titles and descriptions, and make CDC the default choice |
| 3.1.5 | 2023-08-22 | 29534 | Support "options" JDBC URL parameter |
| 3.1.4 | 2023-08-21 | 28687 | Under the hood: Add dependency on Java CDK v0.0.2. |
| 3.1.3 | 2023-08-03 | 28708 | Enable checkpointing snapshots in CDC connections |
| 3.1.2 | 2023-08-01 | 28954 | Fix an issue that prevented use of tables with names containing uppercase letters |
| 3.1.1 | 2023-07-31 | 28892 | Fix an issue that prevented use of cursor columns with names containing uppercase letters |
| 3.1.0 | 2023-07-25 | 28339 | Checkpointing initial load for incremental syncs: enabled for xmin and cursor based only. |
| 3.0.2 | 2023-07-18 | 28336 | Add full-refresh mode back to Xmin syncs. |
| 3.0.1 | 2023-07-14 | 28345 | Increment patch to trigger a rebuild |
| 3.0.0 | 2023-07-12 | 27442 | Set _ab_cdc_lsn as the source defined cursor for CDC mode to prepare for Destination v2 normalization |
| 2.1.1 | 2023-07-06 | 26723 | Add new xmin replication method. |
| 2.1.0 | 2023-06-26 | 27737 | License Update: Elv2 |
| 2.0.34 | 2023-06-20 | 27212 | Fix silent exception swallowing in StreamingJdbcDatabase |
| 2.0.33 | 2023-06-01 | 26873 | Add prepareThreshold=0 to JDBC url to mitigate PGBouncer prepared statement [X] already exists. |
| 2.0.32 | 2023-05-31 | 26810 | Remove incremental sync estimate from Postgres to increase performance. |
| 2.0.31 | 2023-05-25 | 26633 | Collect and log information related to full vacuum operation in db |
| 2.0.30 | 2023-05-25 | 26473 | CDC : Limit queue size |
| 2.0.29 | 2023-05-18 | 25898 | Translate Numeric values without decimal, e.g: NUMERIC(38,0), as BigInt instead of Double |
| 2.0.28 | 2023-04-27 | 25401 | CDC : Upgrade Debezium to version 2.2.0 |
| 2.0.27 | 2023-04-26 | 24971 | Emit stream status updates |
| 2.0.26 | 2023-04-26 | 25560 | Revert some logging changes |
| 2.0.25 | 2023-04-24 | 25459 | Better logging formatting |
| 2.0.24 | 2023-04-19 | 25345 | Logging : Log database indexes per stream |
| 2.0.23 | 2023-04-19 | 24582 | CDC : Enable frequent state emission during incremental syncs + refactor for performance improvement |
| 2.0.22 | 2023-04-17 | 25220 | Logging changes : Log additional metadata & clean up noisy logs |
| 2.0.21 | 2023-04-12 | 25131 | Make Client Certificate and Client Key always show |
| 2.0.20 | 2023-04-11 | 24859 | Removed SSL toggle and rely on SSL mode dropdown to enable/disable SSL |
| 2.0.19 | 2023-04-11 | 24656 | CDC minor refactor |
| 2.0.18 | 2023-04-06 | 24820 | Fix data loss bug during an initial failed non-CDC incremental sync |
| 2.0.17 | 2023-04-05 | 24622 | Allow streams not in CDC publication to be synced in Full-refresh mode |
| 2.0.16 | 2023-04-05 | 24895 | Fix spec for cloud |
| 2.0.15 | 2023-04-04 | 24833 | Fix Debezium retry policy configuration |
| 2.0.14 | 2023-04-03 | 24609 | Disallow the "disable" SSL Modes |
| 2.0.13 | 2023-03-28 | 24166 | Fix InterruptedException bug during Debezium shutdown |
| 2.0.12 | 2023-03-27 | 24529 | Add CDC checkpoint state messages |
| 2.0.11 | 2023-03-23 | 24446 | Set default SSL Mode to require in strict-encrypt |
| 2.0.10 | 2023-03-23 | 24417 | Add field groups and titles to improve display of connector setup form |
| 2.0.9 | 2023-03-22 | 20760 | Removed redundant date-time datatypes formatting |
| 2.0.8 | 2023-03-22 | 24255 | Add field groups and titles to improve display of connector setup form |
| 2.0.7 | 2023-03-21 | 24207 | Fix incorrect schema change warning in CDC mode |
| 2.0.6 | 2023-03-21 | 24271 | Fix NPE in CDC mode |
| 2.0.5 | 2023-03-21 | 21533 | Add integration with datadog |
| 2.0.4 | 2023-03-21 | 24147 | Fix error with CDC checkpointing |
| 2.0.3 | 2023-03-14 | 24000 | Removed check method call on read. |
| 2.0.2 | 2023-03-13 | 23112 | Add state checkpointing for CDC sync. |
| 2.0.0 | 2023-03-06 | 23112 | Upgrade Debezium version to 2.1.2 |
| 1.0.51 | 2023-03-02 | 23642 | Revert : Support JSONB datatype for Standard sync mode |
| 1.0.50 | 2023-02-27 | 21695 | Support JSONB datatype for Standard sync mode |
| 1.0.49 | 2023-02-24 | 23383 | Fixed bug with non readable double-quoted values within a database name or column name |
| 1.0.48 | 2023-02-23 | 22623 | Increase max fetch size of JDBC streaming mode |
| 1.0.47 | 2023-02-22 | 22221 | Fix previous versions which doesn't verify privileges correctly, preventing CDC syncs to run. |
| 1.0.46 | 2023-02-21 | 23105 | Include log levels and location information (class, method and line number) with source connector logs published to Airbyte Platform. |
| 1.0.45 | 2023-02-09 | 22221 | Ensures that user has required privileges for CDC syncs. |
| 2023-02-15 | 23028 | ||
| 1.0.44 | 2023-02-06 | 22221 | Exclude new set of system tables when using pg_stat_statements extension. |
| 1.0.43 | 2023-02-06 | 21634 | Improve Standard sync performance by caching objects. |
| 1.0.42 | 2023-01-23 | 21523 | Check for null in cursor values before replacing. |
| 1.0.41 | 2023-01-25 | 20939 | Adjust batch selection memory limits databases. |
| 1.0.40 | 2023-01-24 | 21825 | Put back the original change that will cause an incremental sync to error if table contains a NULL value in cursor column. |
| 1.0.39 | 2023-01-20 | 21683 | Speed up esmtimates for trace messages in non-CDC mode. |
| 1.0.38 | 2023-01-17 | 20436 | Consolidate date/time values mapping for JDBC sources |
| 1.0.37 | 2023-01-17 | 20783 | Emit estimate trace messages for non-CDC mode. |
| 1.0.36 | 2023-01-11 | 21003 | Handle null values for array data types in CDC mode gracefully. |
| 1.0.35 | 2023-01-04 | 20469 | Introduce feature to make LSN commit behaviour configurable. |
| 1.0.34 | 2022-12-13 | 20378 | Improve descriptions |
| 1.0.33 | 2022-12-12 | 18959 | CDC : Don't timeout if snapshot is not complete. |
| 1.0.32 | 2022-12-12 | 20192 | Only throw a warning if cursor column contains null values. |
| 1.0.31 | 2022-12-02 | 19889 | Check before each sync and stop if an incremental sync cursor column contains a null value. |
| 2022-12-02 | 19985 | Reenable incorrectly-disabled wal2json CDC plugin | |
| 1.0.30 | 2022-11-29 | 19024 | Skip tables from schema where user do not have Usage permission during discovery. |
| 1.0.29 | 2022-11-29 | 19623 | Mark PSQLException related to using replica that is configured as a hot standby server as config error. |
| 1.0.28 | 2022-11-28 | 19514 | Adjust batch selection memory limits databases. |
| 1.0.27 | 2022-11-28 | 16990 | Handle arrays data types |
| 1.0.26 | 2022-11-18 | 19551 | Fixes bug with ssl modes |
| 1.0.25 | 2022-11-16 | 19004 | Use Debezium heartbeats to improve CDC replication of large databases. |
| 1.0.24 | 2022-11-07 | 19291 | Default timeout is reduced from 1 min to 10sec |
| 1.0.23 | 2022-11-07 | 19025 | Stop enforce SSL if ssl mode is disabled |
| 1.0.22 | 2022-10-31 | 18538 | Encode database name |
| 1.0.21 | 2022-10-25 | 18256 | Disable allow and prefer ssl modes in CDC mode |
| 1.0.20 | 2022-10-25 | 18383 | Better SSH error handling + messages |
| 1.0.19 | 2022-10-21 | 18263 | Fixes bug introduced in 15833 and adds better error messaging for SSH tunnel in Destinations |
| 1.0.18 | 2022-10-19 | 18087 | Better error messaging for configuration errors (SSH configs, choosing an invalid cursor) |
| 1.0.17 | 2022-10-17 | 18041 | Fixes bug introduced 2022-09-12 with SshTunnel, handles iterator exception properly |
| 1.0.16 | 2022-10-13 | 15535 | Update incremental query to avoid data missing when new data is inserted at the same time as a sync starts under non-CDC incremental mode |
| 1.0.15 | 2022-10-11 | 17782 | Handle 24:00:00 value for Time column |
| 1.0.14 | 2022-10-03 | 17515 | Fix an issue preventing connection using client certificate |
| 1.0.13 | 2022-10-01 | 17459 | Upgrade debezium version to 1.9.6 from 1.9.2 |
| 1.0.12 | 2022-09-27 | 17299 | Improve error handling for strict-encrypt postgres source |
| 1.0.11 | 2022-09-26 | 17131 | Allow nullable columns to be used as cursor |
| 1.0.10 | 2022-09-14 | 15668 | Wrap logs in AirbyteLogMessage |
| 1.0.9 | 2022-09-13 | 16657 | Improve CDC record queueing performance |
| 1.0.8 | 2022-09-08 | 16202 | Adds error messaging factory to UI |
| 1.0.7 | 2022-08-30 | 16114 | Prevent traffic going on an unsecured channel in strict-encryption version of source postgres |
| 1.0.6 | 2022-08-30 | 16138 | Remove unnecessary logging |
| 1.0.5 | 2022-08-25 | 15993 | Add support for connection over SSL in CDC mode |
| 1.0.4 | 2022-08-23 | 15877 | Fix temporal data type bug which was causing failure in CDC mode |
| 1.0.3 | 2022-08-18 | 14356 | DB Sources: only show a table can sync incrementally if at least one column can be used as a cursor field |
| 1.0.2 | 2022-08-11 | 15538 | Allow additional properties in db stream state |
| 1.0.1 | 2022-08-10 | 15496 | Fix state emission in incremental sync |
| 2022-08-10 | 15481 | Fix data handling from WAL logs in CDC mode | |
| 1.0.0 | 2022-08-05 | 15380 | Change connector label to generally_available (requires upgrading your Airbyte platform to v0.40.0-alpha) |
| 0.4.44 | 2022-08-05 | 15342 | Adjust titles and descriptions in spec.json |
| 0.4.43 | 2022-08-03 | 15226 | Make connectionTimeoutMs configurable through JDBC url parameters |
| 0.4.42 | 2022-08-03 | 15273 | Fix a bug in 0.4.36 and correctly parse the CDC initial record waiting time |
| 0.4.41 | 2022-08-03 | 15077 | Sync data from beginning if the LSN is no longer valid in CDC |
| 2022-08-03 | 14903 | Emit state messages more frequently (⛔ this version has a bug; use 1.0.1 instead | |
| 0.4.40 | 2022-08-03 | 15187 | Add support for BCE dates/timestamps |
| 2022-08-03 | 14534 | Align regular and CDC integration tests and data mappers | |
| 0.4.39 | 2022-08-02 | 14801 | Fix multiple log bindings |
| 0.4.38 | 2022-07-26 | 14362 | Integral columns are now discovered as int64 fields. |
| 0.4.37 | 2022-07-22 | 14714 | Clarified error message when invalid cursor column selected |
| 0.4.36 | 2022-07-21 | 14451 | Make initial CDC waiting time configurable (⛔ this version has a bug and will not work; use 0.4.42 instead) |
| 0.4.35 | 2022-07-14 | 14574 | Removed additionalProperties:false from JDBC source connectors |
| 0.4.34 | 2022-07-17 | 13840 | Added the ability to connect using different SSL modes and SSL certificates. |
| 0.4.33 | 2022-07-14 | 14586 | Validate source JDBC url parameters |
| 0.4.32 | 2022-07-07 | 14694 | Force to produce LEGACY state if the use stream capable feature flag is set to false |
| 0.4.31 | 2022-07-07 | 14447 | Under CDC mode, retrieve only those tables included in the publications |
| 0.4.30 | 2022-06-30 | 14251 | Use more simple and comprehensive query to get selectable tables |
| 0.4.29 | 2022-06-29 | 14265 | Upgrade postgresql JDBC version to 42.3.5 |
| 0.4.28 | 2022-06-23 | 14077 | Use the new state management |
| 0.4.26 | 2022-06-17 | 13864 | Updated stacktrace format for any trace message errors |
| 0.4.25 | 2022-06-15 | 13823 | Publish adaptive postgres source that enforces ssl on cloud + Debezium version upgrade to 1.9.2 from 1.4.2 |
| 0.4.24 | 2022-06-14 | 13549 | Fixed truncated precision if the value of microseconds or seconds is 0 |
| 0.4.23 | 2022-06-13 | 13655 | Fixed handling datetime cursors when upgrading from older versions of the connector |
| 0.4.22 | 2022-06-09 | 13655 | Fixed bug with unsupported date-time datatypes during incremental sync |
| 0.4.21 | 2022-06-06 | 13435 | Adjust JDBC fetch size based on max memory and max row size |
| 0.4.20 | 2022-06-02 | 13367 | Added convertion hstore to json format |
| 0.4.19 | 2022-05-25 | 13166 | Added timezone awareness and handle BC dates |
| 0.4.18 | 2022-05-25 | 13083 | Add support for tsquey type |
| 0.4.17 | 2022-05-19 | 13016 | CDC modify schema to allow null values |
| 0.4.16 | 2022-05-14 | 12840 | Added custom JDBC parameters field |
| 0.4.15 | 2022-05-13 | 12834 | Fix the bug that the connector returns empty catalog for Azure Postgres database |
| 0.4.14 | 2022-05-08 | 12689 | Add table retrieval according to role-based SELECT privilege |
| 0.4.13 | 2022-05-05 | 10230 | Explicitly set null value for field in json |
| 0.4.12 | 2022-04-29 | 12480 | Query tables with adaptive fetch size to optimize JDBC memory consumption |
| 0.4.11 | 2022-04-11 | 11729 | Bump mina-sshd from 2.7.0 to 2.8.0 |
| 0.4.10 | 2022-04-08 | 11798 | Fixed roles for fetching materialized view processing |
| 0.4.8 | 2022-02-21 | 10242 | Fixed cursor for old connectors that use non-microsecond format. Now connectors work with both formats |
| 0.4.7 | 2022-02-18 | 10242 | Updated timestamp transformation with microseconds |
| 0.4.6 | 2022-02-14 | 10256 | (unpublished) Add -XX:+ExitOnOutOfMemoryError JVM option |
| 0.4.5 | 2022-02-08 | 10173 | Improved discovering tables in case if user does not have permissions to any table |
| 0.4.4 | 2022-01-26 | 9807 | Update connector fields title/description |
| 0.4.3 | 2022-01-24 | 9554 | Allow handling of java sql date in CDC |
| 0.4.2 | 2022-01-13 | 9360 | Added schema selection |
| 0.4.1 | 2022-01-05 | 9116 | Added materialized views processing |
| 0.4.0 | 2021-12-13 | 8726 | Support all Postgres types |
| 0.3.17 | 2021-12-01 | 8371 | Fixed incorrect handling "\n" in ssh key |
| 0.3.16 | 2021-11-28 | 7995 | Fixed money type with amount > 1000 |
| 0.3.15 | 2021-11-26 | 8066 | Fixed the case, when Views are not listed during schema discovery |
| 0.3.14 | 2021-11-17 | 8010 | Added checking of privileges before table internal discovery |
| 0.3.13 | 2021-10-26 | 7339 | Support or improve support for Interval, Money, Date, various geometric data types, inventory_items, and others |
| 0.3.12 | 2021-09-30 | 6585 | Improved SSH Tunnel key generation steps |
| 0.3.11 | 2021-09-02 | 5742 | Add SSH Tunnel support |
| 0.3.9 | 2021-08-17 | 5304 | Fix CDC OOM issue |
| 0.3.8 | 2021-08-13 | 4699 | Added json config validator |
| 0.3.4 | 2021-06-09 | 3973 | Add AIRBYTE_ENTRYPOINT for Kubernetes support |
| 0.3.3 | 2021-06-08 | 3960 | Add method field in specification parameters |
| 0.3.2 | 2021-05-26 | 3179 | Remove isCDC logging |
| 0.3.1 | 2021-04-21 | 2878 | Set defined cursor for CDC |
| 0.3.0 | 2021-04-21 | 2990 | Support namespaces |
| 0.2.7 | 2021-04-16 | 2923 | SSL spec as optional |
| 0.2.6 | 2021-04-16 | 2757 | Support SSL connection |
| 0.2.5 | 2021-04-12 | 2859 | CDC bugfix |
| 0.2.4 | 2021-04-09 | 2548 | Support CDC |
| 0.2.3 | 2021-03-28 | 2600 | Add NCHAR and NVCHAR support to DB and cursor type casting |
| 0.2.2 | 2021-03-26 | 2460 | Destination supports destination sync mode |
| 0.2.1 | 2021-03-18 | 2488 | Sources support primary keys |
| 0.2.0 | 2021-03-09 | 2238 | Protocol allows future/unknown properties |
| 0.1.13 | 2021-02-02 | 1887 | Migrate AbstractJdbcSource to use iterators |
| 0.1.12 | 2021-01-25 | 1746 | Fix NPE in State Decorator |
| 0.1.11 | 2021-01-25 | 1765 | Add field titles to specification |
| 0.1.10 | 2021-01-19 | 1724 | Fix JdbcSource handling of tables with same names in different schemas |
| 0.1.9 | 2021-01-14 | 1655 | Fix JdbcSource OOM |
| 0.1.8 | 2021-01-13 | 1588 | Handle invalid numeric values in JDBC source |
| 0.1.7 | 2021-01-08 | 1307 | Migrate Postgres and MySql to use new JdbcSource |
| 0.1.6 | 2020-12-09 | 1172 | Support incremental sync |
| 0.1.5 | 2020-11-30 | 1038 | Change JDBC sources to discover more than standard schemas |
| 0.1.4 | 2020-11-30 | 1046 | Add connectors using an index YAML file |